Real-world data is messy — inconsistent definitions and errors in labeling are inevitable. Most analytics models make a hard assumption that the data is correct; they break down under real-world conditions, producing unreliable results when data isn’t pristine. Consequently, companies typically pay to have data labeled, checked, and re-checked: this adds cost, friction, and delays when deploying machine learning.
Sturdy Statistics is different. Our proprietary technology is built to handle noisy data without losing accuracy. Whether your dataset contains occasional mistakes or even systematic errors, our models adapt and extract meaningful insights — no data cleaning required.
The figure below shows an example classification problem with two classes. (The problem has 100 dimensions; for illustration purposes, we only show two of them here.) The top row compares the performance of different classification technologies when the data is perfect: all but the most simple model work adequately.
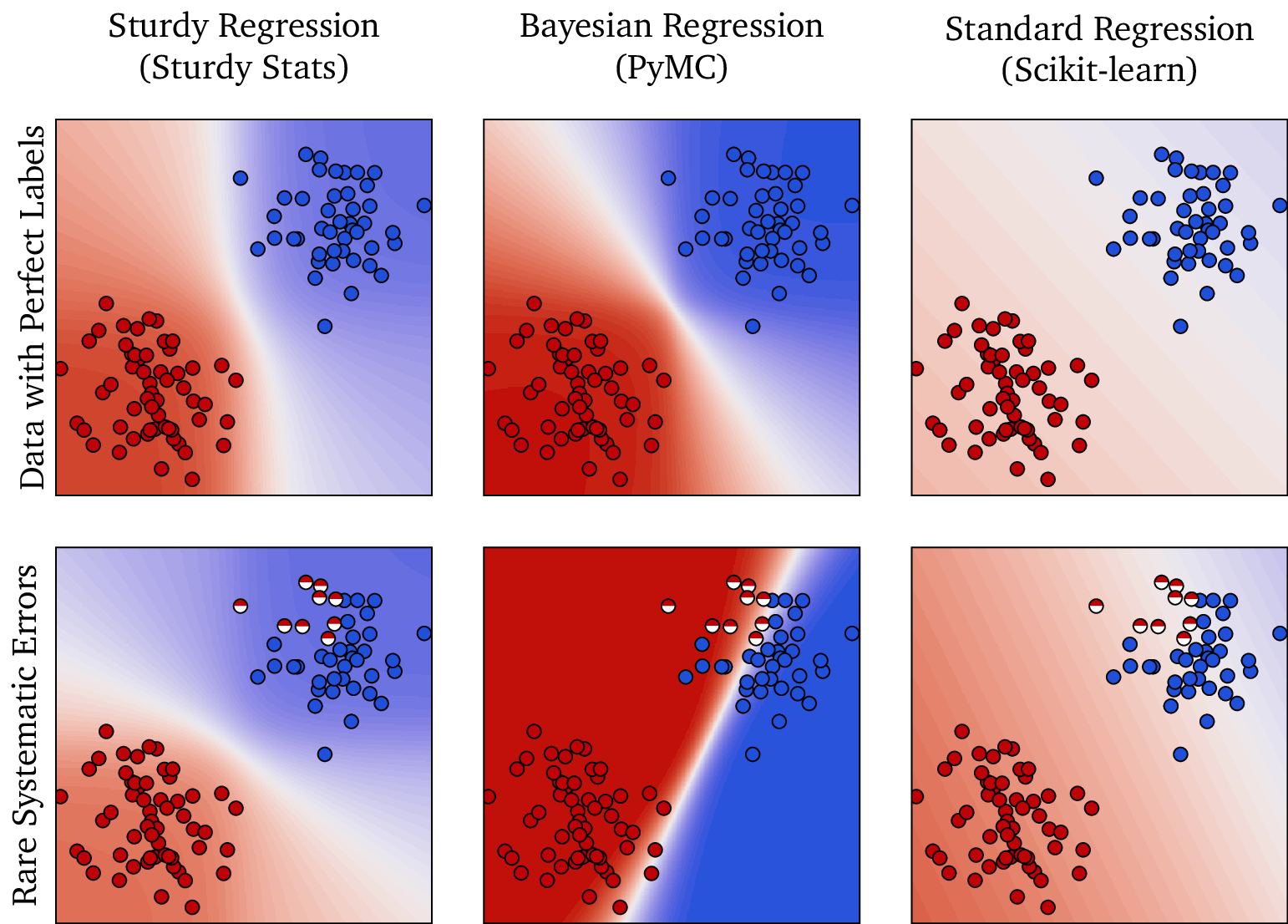
When we introduce systematic errors into the data, however, the results change dramatically. In the bottom row, we have intentionally mis-labeled 10% of the points. Though we only corrupted a small fraction of the data, most models are unstable to errors: they behave erratically and produce the wrong solution. The Study Statistics Sturdy Regression model, however, is unfazed: it still produces the correct result!
This breakthrough ensures that your analyses remain trustworthy and consistent, even when working with imperfect information. Instead of amplifying errors, Sturdy Statistics delivers stable results that remain reliable, no matter the quality of the input data.
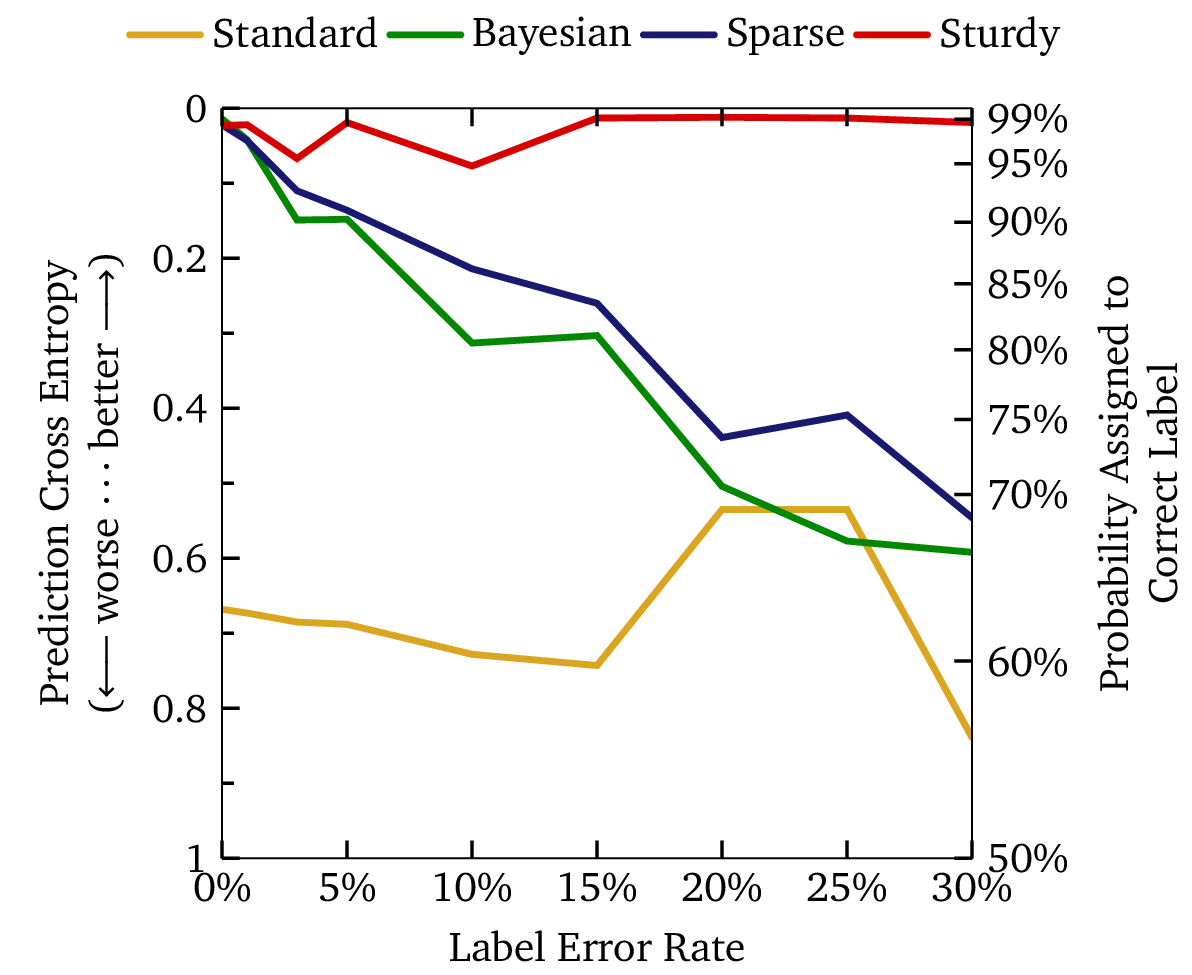
We can better quantify model performance in terms of prediction cross-entropy: if you’re not familiar with this technical term, it effectively represents the (geometric) mean of the confidence that the model assigns to the correct label. The figure below shows how the entropy (or correct confidence) varies for different models as we increase the data error rate. All other models degrade strongly as we introduce errors, but the Sturdy Statistics model is unaffected.
With this capability, businesses can make data-driven decisions confidently — without the burden of perfect data.